지난 글에서 GA를 통해 서비스 이용자와 관련된 다양한 데이터를 활용하고 분석하여 인사이트를 얻어 보았다. GA는 높은 편의성과 접근성으로 인해 데이터 분석에서 굉장히 중요한 툴이나, GA만으로는 서비스 개선 및 이용자 행태 분석에 대한 데이터와 인사이트를 100% 얻기에는 부족하다. 데이터 분석을 위해서는 GA 이외에도 파이썬, SQL, 태블로, R 등의 다양한 분석툴 활용 능력이 필요하다. 그렇기에 이번에는 파이썬, 태블로를 활용하여 서비스와 관련된 가설을 설정하고 데이터를 통해 가설을 검증한다. Kaggle에서 서비스 관련 데이터를 추출하여 파이썬을 통해 EDA 및 전처리를 진행한 후 시각화하여 최종적으로 인사이트를 얻는 과정을 밟을 것이다.
Kaggle 데이터 서치

Kaggle은 다양한 데이터를 이용할 수 있는 사이트로, 음식/경제/스포츠/사회 등 다양한 분야의 데이터를 얻을 수 있으며 이를 머신 러닝, 데이터 분석 및 시각화 등에 활용할 수 있다. 이번에 나는 'Facebook Ad-Campaigns Analysis/Sales-Prediction'이라는 데이터를 분석해보기로 했다. 해당 데이터는 익명 서비스의 소셜 미디어 광고 캠페인에 대한 CSV 파일로 전환, 클릭, 광고 노출 수부터 이용자의 성별, 연령 등의 데이터를 담고 있다. 해당 데이터의 Column은 다음과 같다.
1) ad_id: 각 광고에 대한 Unique한 id
2) xyzcampaignid: 서비스의 각 캠페인에 대한 id(진행된 캠페인은 총 3개)
3) fbcampaignid: 페이스북이 각각의 캠페인을 트래킹하는데 이용한 id
4) age: 광고가 노출된 사람들의 연령대
5) gender: 광고가 노출된 사람들의 성별
6) interest: 광고가 노출된 사람들의 관심사를 나타내는 코드
7) Impressions: 광고가 노출된 횟수
8) Clicks: 광고를 클릭한 횟수
9) Spent: 광고 클릭 수 하나 당 투자한 비용
10) Total conversion: 광고를 보고 나서 서비스에 대해 문의한 횟수
11) Approved conversion: 광고를 보고 나서 서비스를 구매한 횟수
가설 설정

Column 및 실제 데이터를 살펴본 후에 도출한 가설은 다음과 같다.
1) 이전에 진행한 페이스북 광고 캠페인 중 3번째 광고 캠페인에 노출된 고객들은 다른 캠페인에 노출된 고객들보다 더 많이 구매를 했을 것이다.
2) 캠페인/연령/성별로 세분화한 고객 그룹 중 3번째 캠페인에 노출된 30대 초반 여자는 광고를 보고 나서 서비스를 구매한 횟수가 가장 많을 것이다(해당 서비스의 핵심 고객은 30대 초반 여자라는 가정에서 나온 가설)
3) 더 많은 비용을 투자하여 광고 노출 횟수를 높여 이용자의 광고 노출 수를 늘린다면 이용자의 구매 수가 더 늘어날 것이다.
세운 가설이 실제 맞는지 데이터를 통해 확인해보자.
데이터 EDA 및 전처리 by 파이썬

파이썬을 활용하여 해당 데이터 셋의 패턴을 파악하고 인사이트를 도출하는 EDA 및 전처리를 해보자.

가장 먼저 해당 과정에 필요한 pandas, matplotlib 등의 라이브러리를 가져온다.

그 다음으로, 분석할 CSV 파일을 불러온다.
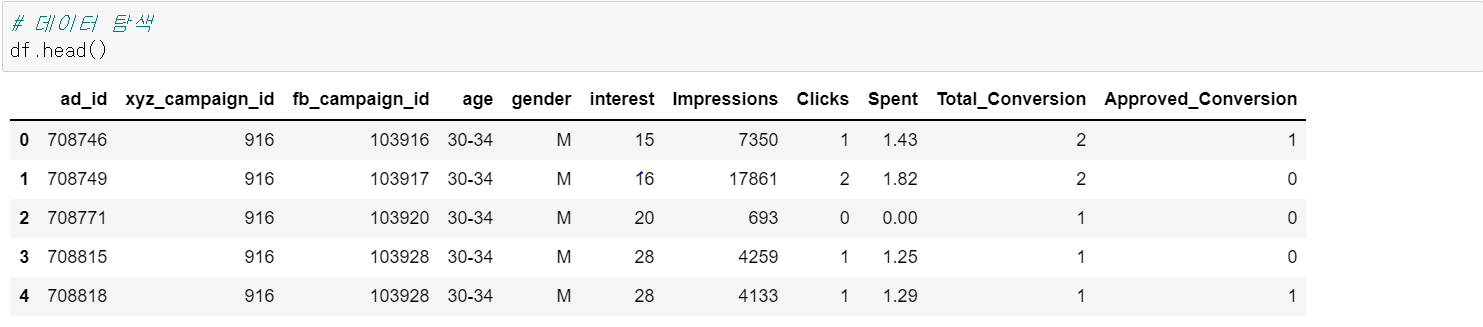

본격적으로 탐색을 시작하기 위해 head()와 tail()을 통해 데이터 일부를 확인해본다.

shape를 통해 Column 및 Record의 갯수를 확인한다.
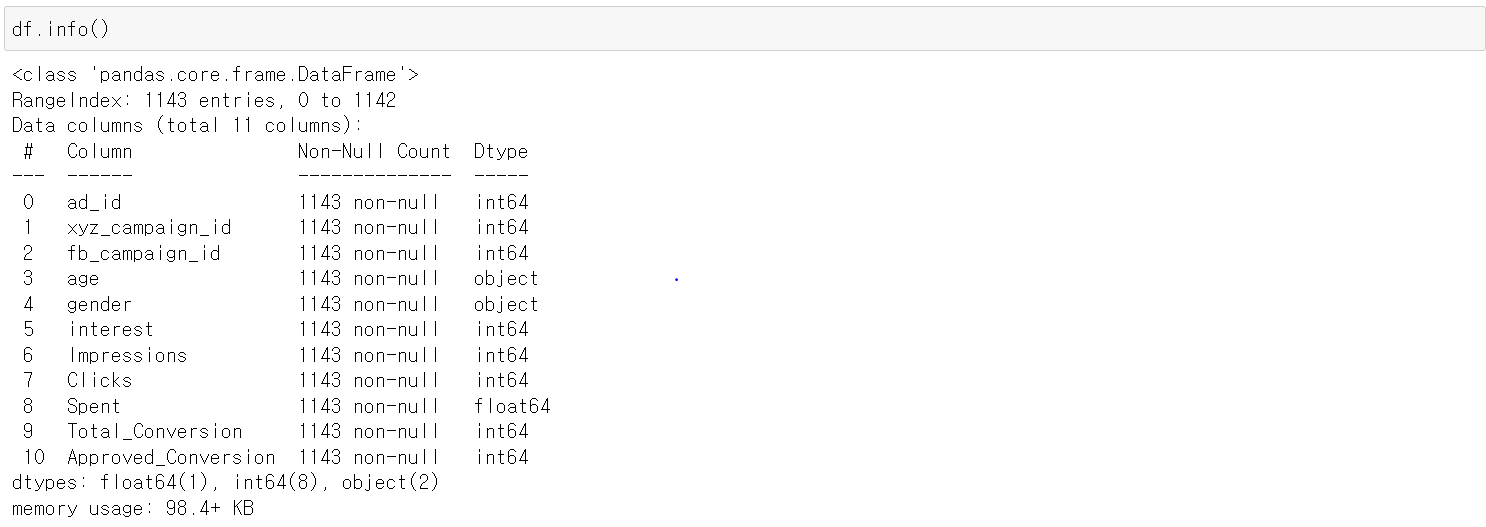
info()를 통해 각 Column의 이름, Non-Null Count, 데이터 타입을 확인한다. 각 Column의 데이터 타입은 문제가 없는 것으로 보이며, Non-Null 값의 갯수 역시 모든 Column이 같은 것으로 보이는데, Null 값의 갯수를 확인해보자.
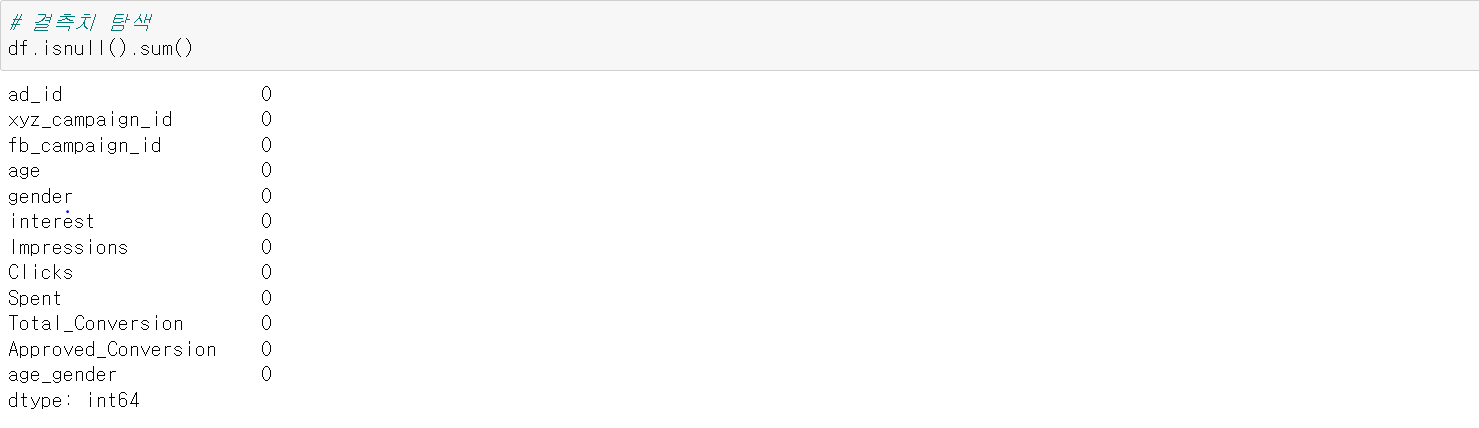
isnull().sum()을 통해 Column별 Null 값의 갯수를 확인해보았는데, Null 값이 한 개도 존재하지 않는다. 결측치가 없기에 dropna나 fillna과 같은 결측치 관련 작업은 하지 않아도 된다. 분석에 쓰기 꽤나 좋은 데이터이다.
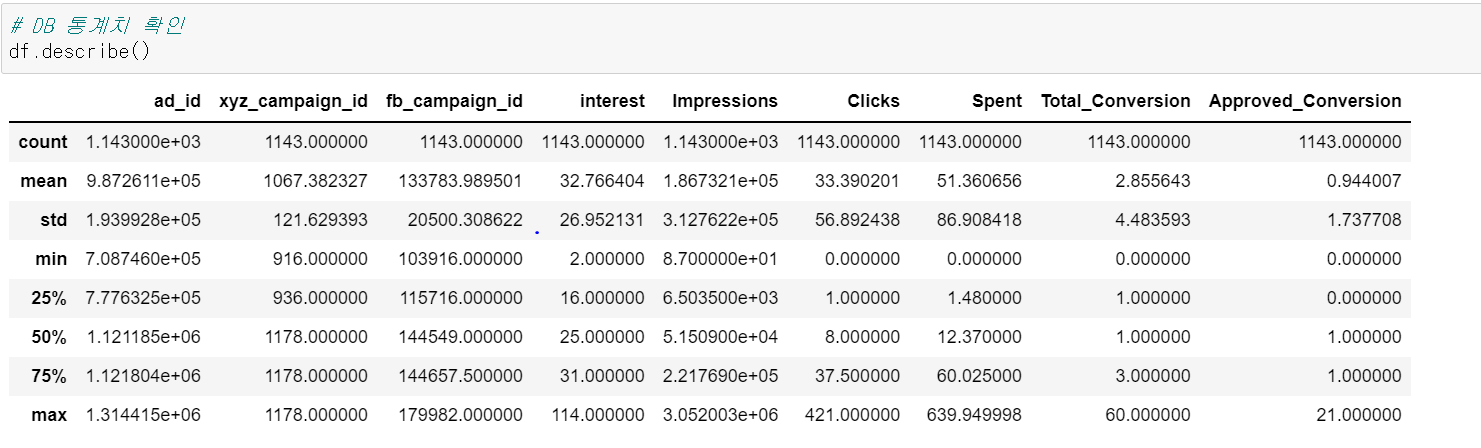
describe()를 통해 데이터의 카운트, 평균, 표준편차, 최솟값, 최댓값 등의 통계치를 확인할 수 있다. 모델링의 경우 통계치를 확인하고 나서, 이상치 제거와 같은 작업을 수행할 때가 많으나 이번 분석은 모델링을 하지 않는다는 점, 시각화에 문제가 될 이상치가 발견되지 않는다는 점 때문에 이상치 탐색은 생략해도 될 것 같다.

len()과 unique()를 통해 기업이 진행한 캠페인의 갯수와 명칭을 확인한다.

단순 숫자보다는 캠페인 명을 Campaign1,2,3으로 설정하는 것이 분석 시 가독성이 좋다고 생각하여 replace()를 통해 이름을 변경하였다.
duplicated()를 통해 데이터 내에 혹시나 존재할 중복 열을 확인한다. 확인 결과 중복되는 열은 존재하지 않는다.
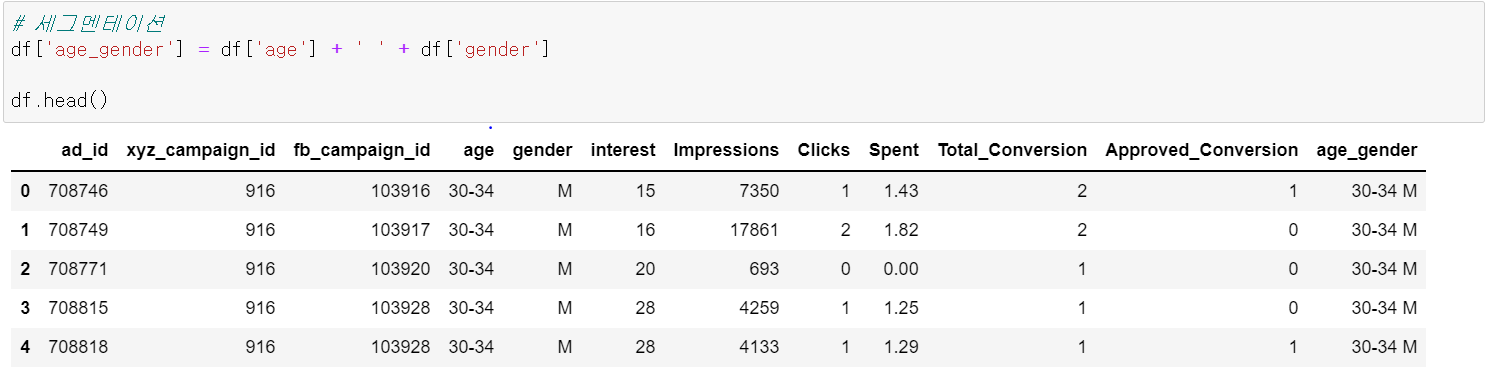
광고 노출 및 전환을 한 이용자들을 단순히 성별이나 연령 한 가지 카테고리로만 세그멘테이션하기보다는 연령과 성별을 모두 이용하여 세그멘테이션한다면 보다 효율적인 타겟팅 및 인사이트 도출이 가능하기 때문에 age와 gender를 합친 age_gender Column을 새로 만들었다.
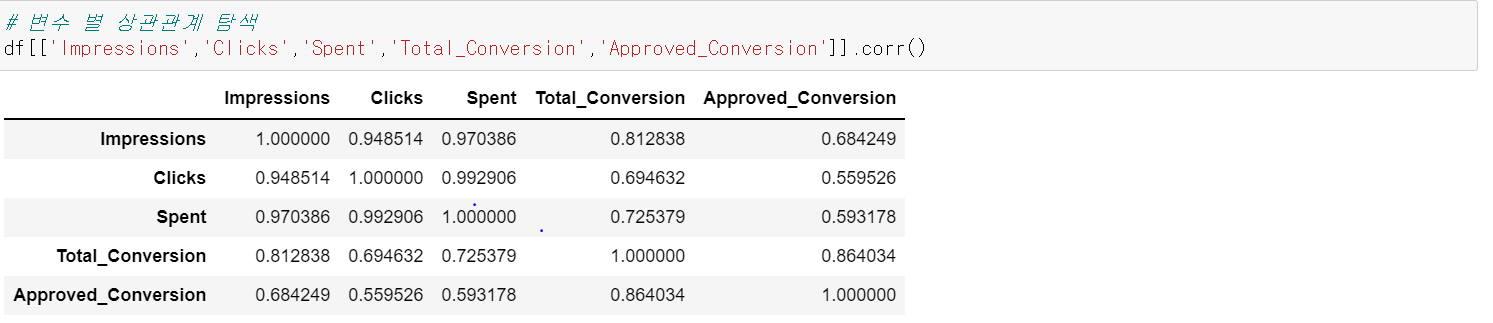
다음으로, corr()을 통해 Approved_Conversion, 즉 구매라는 전환과 다른 변수들에 대한 상관관계를 확인해보았다. 테이블에 나오는 값은 상관계수로 해당 값이 1에 가까울수록 두 변수는 강한 양의 상관성을 가지고 있다고 볼 수 있다. 지금은 간략하게 살펴보고 이후 히트맵 차트에서 보다 자세하게 살펴보자.
데이터 시각화 by 파이썬
지금부터는 단순히 텍스트만으로 데이터를 탐색하는 것에서 더 나아가 시각화된 차트를 통해 인사이트를 도출하고 가설을 검증해볼 것이다. 해당 과정 역시 파이썬으로 진행될 것이며, Matplotlib과 Seaborn 라이브러리가 쓰일 예정이다.

먼저 countplot을 통해 데이터 내 성별 count를 확인해보자. 데이터에는 남성의 레코드가 더 많긴 하나 여성 레코드보다 유의미하게 큰 정도는 아닌 것으로 보인다.

다음은 countplot으로 연령의 count를 측정할 차례이다. 연령의 경우에는 30-34/35-39/40-44/45-49 4개로 분류되었으며, 다른 연령대에 비해 30-34의 레코드가 많은 편이다.
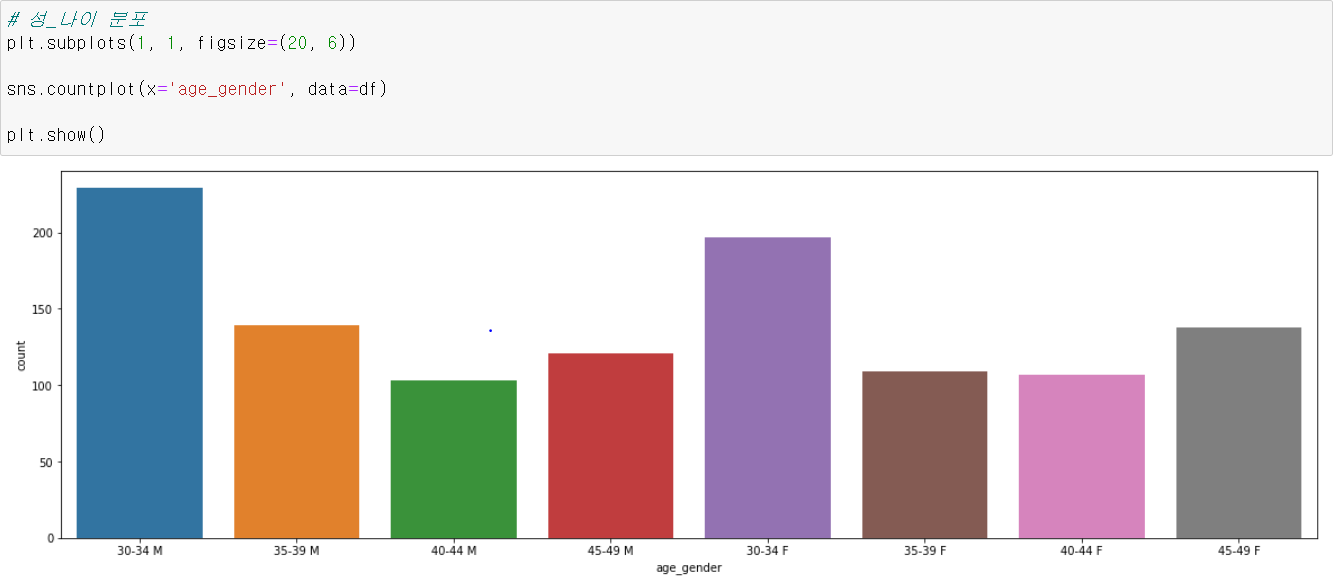
이제 앞선 세그멘테이션 과정을 통해 추가한 Column인 age_gender의 카운트를 확인해보자. 여전히 다른 연령대에 비해 30-34 레코드가 많은 수를 보여주고 있으며, 30-34 남성 레코드가 여성 레코드에 비해 더 많은 카운트를 보여주고 있다. 그러나 레코드가 많다는 것은 유의미한 인사이트를 도출하기에는 아직 부족하다. 더 시각화를 진행해보자.

박스 플롯을 통해 Impressions, Clicks, Spent, Total_Conversion, Approved_Conversion Column의 최솟값/최댓값/중위수 등을 확인한다. 해당 차트를 통해서도 아직 가설을 검증하기에는 부족해보인다.
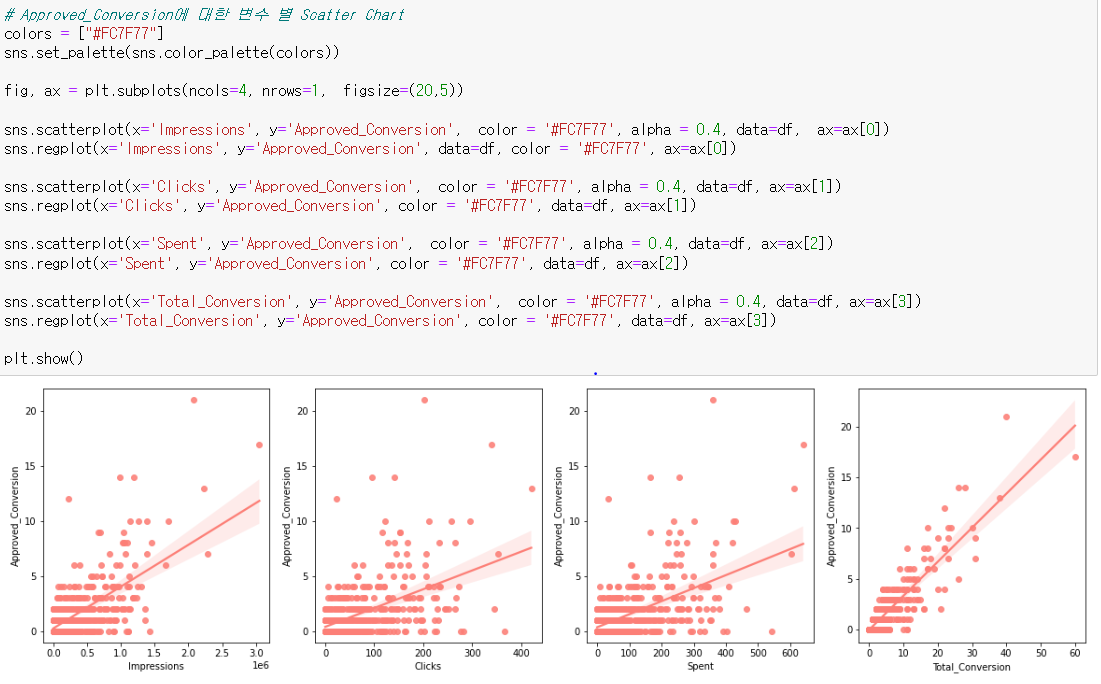
다음으로 산점도 차트를 통해 변수 간 상관관계를 확인해보자. 각 차트에서는 우리에게 가장 중요한 변수인 Approved_Conversion과 다른 변수 간의 상관관계를 확인할 수 있는데, 산점도가 45도의 우상향 직선에 가까운 곡선을 보여주는 변수는 Impressions와 Total_Conversion 차트로 해당 변수들은 다른 변수들에 비해 Approved_Conversion과 양의 관계를 가지고 있음을 확인할 수 있다. 즉, 가설 3인 "더 많은 비용을 투자하여 광고 노출 횟수를 높여 이용자의 광고 노출 수를 늘린다면 이용자의 구매 수가 더 늘어날 것이다"가 맞는 것임을 확인할 수 있는데, 보다 정확히 알아보기 위해 히트맵 차트를 활용해보자.
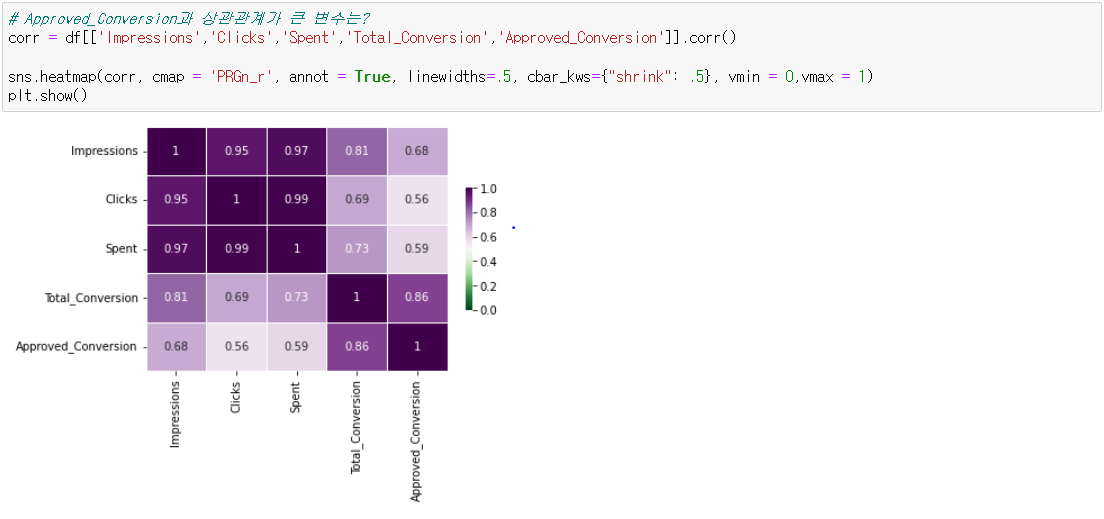
앞선 corr()를 통해 본 상관관계 및 상관계수를 살펴볼 수 있는 히트맵 차트이다. 해당 차트에서 역시 Approved_Conversion과 상관 계수가 높은 변수는 Impressions와 Total_Conversion임을 확인할 수 있다. 상관계수가 0.5을 넘는 경우 유의미한 양의 관계를 가지고 있다고 간주할 수 있기에, Impressions를 높일 경우 Approved_Conversion을 높일 수 있다고 볼 수 있을 것이다(한 가지 유의해야할 것은 상관관계가 인과관계를 의미하지는 않기에 해당 결론이 틀릴 수도 있다는 점이다. 실무에서는 이를 검증하기 위해 또 다른 분석 및 조사가 함께 이루어져야 할 것으로 보인다.) 즉, 가설 3 "더 많은 비용을 투자하여 광고 노출 횟수를 높여 이용자의 광고 노출 수를 늘린다면 이용자의 구매 수가 더 늘어날 것이다"은 어느 정도 맞는 가설인 것이다!
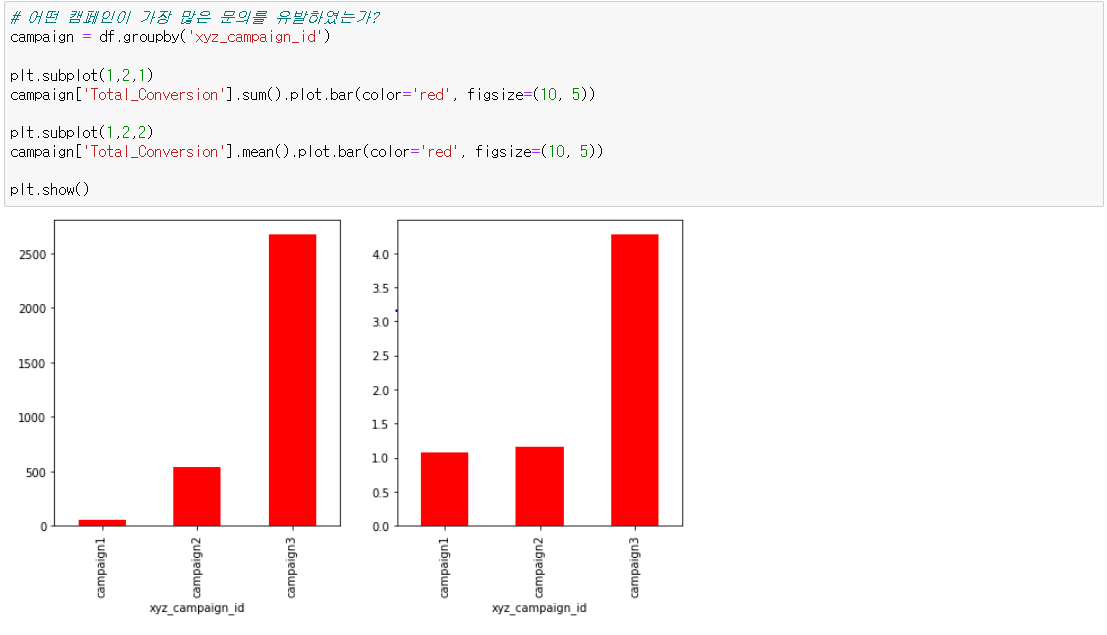
이제 다른 가설들을 검증하기 위해 시각화를 다시 진행해보자. 이번에는 3개의 캠페인 중 하나에 노출된 고객이 얼마나 많이 문의를 하였는지 보여주는 막대 차트를 만들었다. 좌측 차트는 캠페인별 문의수 합계이며, 우측 차트는 캠페인별 1인당 평균 문의수이다. 이를 통해 우리는 Campaign3에 노출된 고객들이 다른 캠페인에 노출된 고객들에 비해 더 많이 문의를 했음을 확인할 수 있다. Total_Conversion은 Approved_Conversion과 높은 상관 계수를 가지는 만큼, 지금 현재 상황에서 Campaing3는 구매 역시 다른 캠페인에 비해 많이 유발했을 것이라고 추측할 수 있을 것이다.

역시나 구매의 경우에도 합계나 평균 모두 Campaign3에 노출된 고객들이 유의미하게 더 많은 구매수를 보여주고 있다. 이를 통해 Campaign3는 다른 캠페인들에 비해 더 많은 고객 구매를 유발한다는 인사이트를 얻을 수 있다. 즉, 앞서 살펴본 가설 중 "이전에 진행한 페이스북 광고 캠페인 중 3번째 광고 캠페인에 노출된 고객들은 다른 캠페인에 노출된 고객들보다 더 많이 구매를 했을 것이다."라는 가설 1 역시 맞는 가설인 것이다.

마지막으로, 가설 1을 검증하기 위해 캠페인 및 연령 별 구매 수를 보여주는 막대 차트를 제작했다. 해당 차트를 살펴보면 Campagin3에 노출된 30-34 고객들은 다른 고객 그룹에 비해 보다 많은 구매를 하고 있음을 확인할 수 있다.

다음으로는, 캠페인/성별 구매 수를 보여주는 막대 차트를 만들었다. 해당 차트를 살펴보면 합계에서는 Campaign3에 노출된 남성 고객이 가장 많은 구매 수를 보여주며, 평균에서는 Campaign3에 노출된 여성 고객이 가장 많이 구매를 했음을 확인할 수 있다.
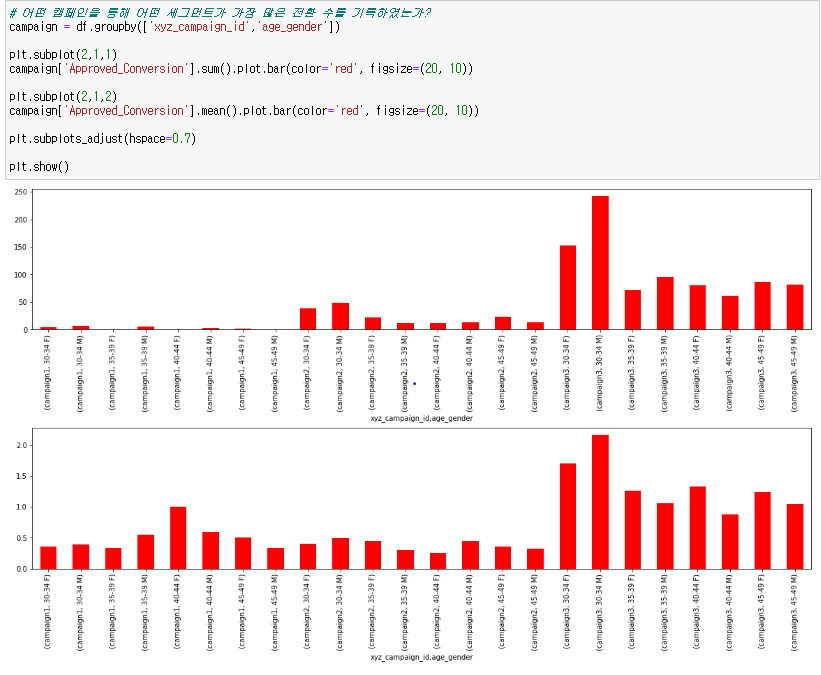
마지막으로, 캠페인/연령/성별 모두를 고려하여 세분화한 고객 그룹 별 구매 수 막대 차트를 살펴볼 차례이다. 해당 차트를 살펴보면 Campagin3에 노출된 30-34 남자가 가장 많은 구매수를 보여주고 있음을 확인할 수 있다. 즉, 앞서 살펴본 가설 2 "캠페인/연령/성별로 세분화한 고객 그룹 중 3번째 캠페인에 노출된 30대 초반 여자가 광고를 보고 나서 서비스를 구매한 횟수가 가장 많을 것이다"는 틀린 가설임을 확인할 수 있다.

이번에는 실제 데이터를 활용하여 분석 및 시각화를 진행해보았는데.. 매일 데이터 프로젝트는 팀 단위로 하다보니 혼자서 분석 및 시각화를 하는 과정이 너무 오랜만이라 어색하게 느껴졌다. 또한 이번 껀 데일리 과제라 몇 시간만에 뚝딱한 것도 있어서 그런지 솔직히 말해서 만족스러운 결과물은 아닌 것 같다. 전처리나 EDA는 해도 해도 능숙해지지 않는 느낌.. 프로젝트 함께 하는 팀원 친구들이 보고 싶다..ㅠ 그나저나 태블로랑 피그마로 마무리하면 훨씬 보기 좋은 차트랑 대시보드가 나올 것 같은데, 다른 거 할 게 많아서 굳이라는 생각도 든다. 시간 남으면 해야지.
'기획' 카테고리의 다른 글
| 토스 Open API 살펴보기 (0) | 2022.06.24 |
|---|---|
| AARRR로 보는 라프텔 서비스 (0) | 2022.06.09 |